ディープラーニング(深層学習)の成果が世界中で報告されているが、膨大な学習用データが必要となる。また基本的に大容量のデータをサーバーに集める必要がある。
Googleは先頃、そのデータ処理過程の効率性を高めうる、連合学習(Federated Learning)という手法について発表した。これは、すべてのデータをサーバーに集めてAIを学習する従来の方法とは異なり、ユーザーが使用するスマートフォンでデータを処理、モデルを強化し、そのモデルを集めより洗練されたモデルを作成・再配布するという形式を取る。
Googleの研究者であるBlaise Aguera y Arcas氏によれば、「深層学習という概念は1959年から登場したが、最近大きく注目されている理由はコンピューティング性能の飛躍的な発展とデータの増加のおかげである。プロセッサの演算性能は過去数年間で急速に成長しており、スマートフォン程の大きさの機器でもデータを処理することが可能になった。そのため人工知能は、ユーザーとより近い場所でリアルタイムに動作することができる」と説明する。
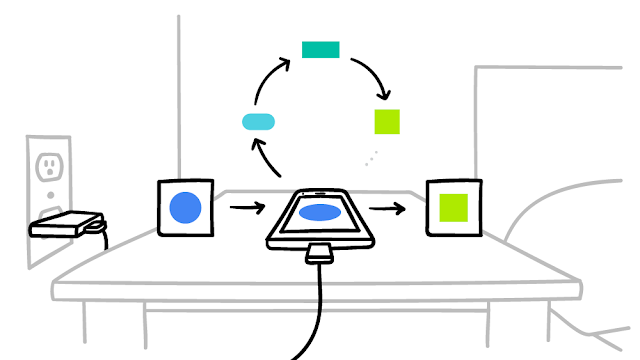
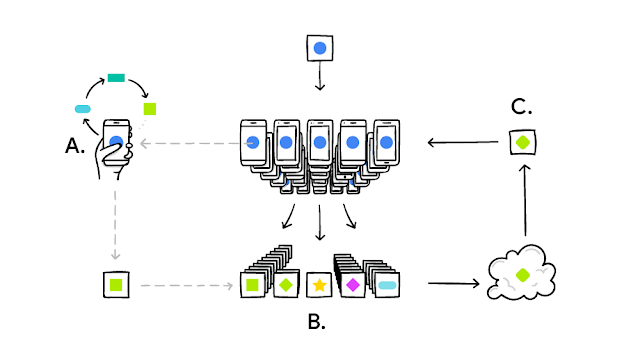
連合学習が動作するプロセスは以下の通りだ。まずスマートフォンに搭載された学習アルゴリズムは、個々のユーザーの行動パターンに基づいて学習。自らのモデルを強化し、ユーザーよりふさわしいスマートフォン使用環境を提供する。ユーザーがスマートフォンに充電器を接続している間、もしくは夜間には、同モデルがサーバーに送信され他のモデルとの情報を共有。より良いパフォーマンスを発揮するためのモデルへと進化する。なお、この過程では、ユーザーの個人情報は共有されず、モデルだけが共有される。そのため、個人情報の流出の可能性は排除されているというのがグーグル側の説明だ。
Googleは連合学習を「学術大会」や「学会」に例える。研究者が研究成果を発表すると、他の研究者にもそのノウハウが共有されるが、それを人工知能が行っているという訳だ。
Arcas氏は、人工知能は信じられないほど大きなデータセットを使って学習開始するのが普通。データセンター内に分散した人工ニューラルネットワークは、各データを処理し中央サーバーに送る。そのプロセスを繰り返してモデルを改善し、サーバーを通じてユーザーのスマートフォンに展開する形だった。一方、連合学習は人工ニューラルネットワークをユーザー個人のデバイスに分散する一種のエッジ・コンピューティングのような形だと説明している。
連合学習のビジネス的メリットとしては、比較的少ないインフラでも最適化した人工知能モデルを開発できる点だとされている。トラフィックの負担も少なく、個人情報流出のリスクも低いとされている。ユーザーの立場としては、遅延時間の減退などより豊かなデジタル体験が可能となる。今後、どんな新しいAI技術が登場するか、引き続き注目していきたい。
Photo by Google AI Blog