AP通信の「ワード・スミス」は、企業業績の記事を書くロボット記者だ。人間の記者が作成可能な記事数が四半期あたり300なのに比べ、ワード・スミスは4000以上の記事を作成することができる。そのように、人工知能を搭載したロボットが人間に代わって記事を書くプロジェクトが増え始めているが、限界点も指摘されてきた。それは単純なストレート記事しか作成できず、テーマを選んだり、現象を解析することができないというものだ。しかし、そのような限界は徐々に突破されていくかもしれない。
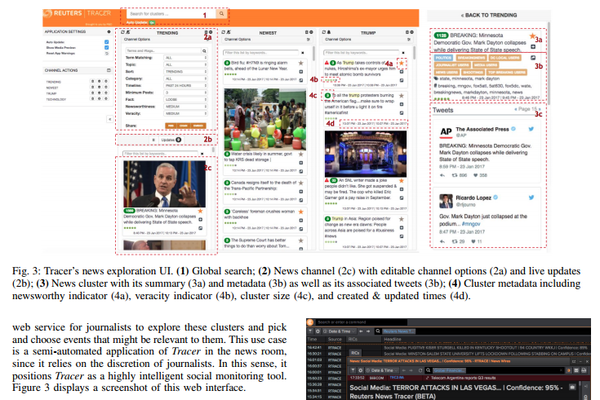
最近、ロイターの研究チームが発表した報告書「Reuters Tracer: Toward Automated News Production Using Large Scale Social Media Data」は、「インターネットの出現、そしてそれに伴う情報量の増加によって、(人間の)記者は正確かつ迅速にニュースを配信することがますます難しくなっている」と困難を吐露する文章から始まり、次いで、人工知能を使って速報を自動化するシステム「ロイター・トレーサー(Reuters Tracer)」を実験中だと言及した。これは、ロイター研究チームと中国アリババグループがともに開発を進めるロボット記者で、ソーシャルメディアを利用した一種の“情報追跡システム”となる。
従来のロボット記者は、特定の形式に沿って数字だけを入れ替え新たなニュース(地震やスポーツ速報など)としてきたが、ロイター・トレーサーはそれらとは機能が異なり、自ら問題を探しだす“能動性”を持つ。より具体的には、データマイニングと機械学習で関連性の高いテーマを選択し、優先順位を決めた後、タイトルとサマリーを付け記事を作成する。
ロボット記者や人工知能が自らテーマを選択するという事例はこれまで考えられぬことだったが、一体、どのような仕組みなのだろうか。
ロイター・トレーサーはまず、ツイッターで「データの流れ」をつかむことから始める。毎日、ツイート全体の2%(約1200万件)を抽出。そのうち半分はランダム、残りの半分のロイターが作成したアカウントリストから抽出する。後者には企業やマスコミ、有名人などが含まれる。次いで、ツイートの同時多発性からニュースの発生時期を特定する。
ニュースを特定・分類した後、複数のアルゴリズムを利用して作成すべき記事の優先順位を決める。ロイター・トレーサーは、毎日1200万件のツイートを処理すると前述したが、そのうち80%をノイズとして除去。残りの20%については、6000種類のニュースに分類する。そのプロセスは、10種類のアルゴリズムを実行する13台のサーバー上で実行されている。
抽出されたツイートは、CNNやニューヨーク・タイムズ、BBCなど世界の主要メディアの公式Twitterアカウントのツイート、ロイターが作成したニュースのデータベースとも比較される。その際、ニュースの発生位置も特定される。
そのようにツイートを分析してニュースを判断するとしたら、内容の真偽も重要となってくる。そこでロイター・トレーサーはソース(Webページなど)を確認。並行して、フェイクニュースや風刺ニュースを掲載するサイトのデータとも比較作業も行う。
テスト期間中、ロイター・トレーサーのシステムはある程度しっかりと動作したとロイター研究チームは伝えている。 ロイターは、作成された記事をBBCやCNNなど主要な報道機関のニュースフィードに掲載された記事と比較した。そして「競合他社に負けない精度と適時性、信頼性を通じてニュースを検索・展開することができた(中略)2%のツイッターデータを抽出することで、約70%のニュースをカバーすることができた」と結論付けている。
今後、ツイッターをデータソースとする以上、悪意ある人々がソースを歪曲する可能性を考慮してアップデートしていく必要があるだろう。しかし研究の動向を見る限り、AIがニュース作成を担う範囲が広がり続けるということだけは間違いなさそうである。
Photo by arxiv.org